




The real power of a relational database is when we make multiple tables and make links between those tables. The act of deciding how to break up your application data into multiple tables and establishing the relationships between the two tables is called data modeling. The design document that shows the tables and their relationships is called a data model.
Data modeling is a relatively sophisticated skill and we will only introduce the most basic concepts of relational data modeling in this section. For more detail on data modeling you can start with:
http://en.wikipedia.org/wiki/Relational_model
Let’s say for our Twitter spider application, instead of just counting a person’s friends, we wanted to keep a list of all of the incoming relationships so we could find a list of everyone who is following a particular account.
Since everyone will potentially have many accounts that follow them, we cannot simply add a single column to our Twitter table. So we create a new table that keeps track of pairs of friends. The following is a simple way of making such a table:
CREATE TABLE Pals (from_friend TEXT, to_friend TEXT)
Each time we encounter a person who drchuck is following, we would insert a row of the form:
INSERT INTO Pals (from_friend,to_friend) VALUES ('drchuck', 'lhawthorn')
As we are processing the 20 friends from the drchuck Twitter feed, we will insert 20 records with “drchuck” as the first parameter so we will end up duplicating the string many times in the database.
This duplication of string data violates the best practices for database normalization which basically states that we should never put the same string data in the database more than once. If we need the data more than once, we create a numeric key for the data and reference the actual data using this key.
In practical terms, a string takes up a lot more space than an integer on the disk and in the memory of our computer and takes more processor time to compare and sort. If we only have a few hundred entries the storage and processor time hardly matters. But if we have a million people in our database and a possibility of 100 million friend links, it is important to be able to scan data as quickly as possible.
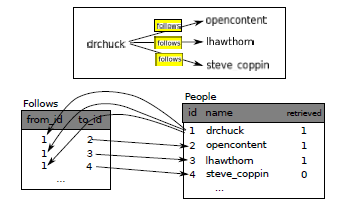
We will store our Twitter accounts in a table named People instead of the Twitter table used in the previous example. The People table has an additional column to store the numeric key associated with the row for this Twitter user. SQLite has a feature that automatically adds the key value for any row we insert into a table using a special type of data column (INTEGER PRIMARY KEY).
We can create the People table with this additional id column as follows:
CREATE TABLE People (id INTEGER PRIMARY KEY, name TEXT UNIQUE, retrieved INTEGER)
Notice that we are no longer maintaining a friend count in each row of the People table. When we select INTEGER PRIMARY KEY as the type of our id column, we are indicating that we would like SQLite to manage this column and assign a unique numeric key to each row we insert automatically. We also add the keyword UNIQUE to indicate that we will not allow SQLite to insert two rows with the same value for name.
Now instead of creating the table Pals above, we create a table called Follows with two integer columns from_id and to_id and a constraint on the table that the combination of from_id and to_id must be unique in this table (i.e. we cannot insert duplicate rows) in our database.
CREATE TABLE Follows (from_id INTEGER, to_id INTEGER, UNIQUE(from_id, to_id) )
When we add UNIQUE clauses to our tables, we are communicating a set of rules that we are asking the database to enforce when we attempt to insert records. We are creating these rules as a convenience in our programs as we will see in a moment. The rules both keep us from making mistakes and make it simpler to write some of our code.
In essence, in creating this Follows table, we are modelling a ”relationship” where one person ”follows” someone else and representing it with a pair of numbers indicating that (a) the people are connected and (b) the direction of the relationship.
- 瀏覽次數:2162
