




If we remove information about the last account at a branch (Downtown), all of the branch information disappears
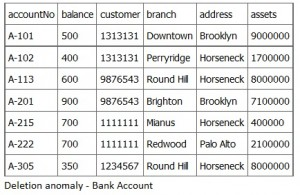
The problem is that after deleting the row, we don’t know where the Downtown branch is located and we lose all information regarding customer ‘1313131’. To avoid these kinds of update/delete problems we need to decompose the original table into several smaller tables where each table has minimal overlap with other tables. Typically, each table contains information about one entity (e.g. branch, customer, …)
The Bank Accounts tables should appear as follows
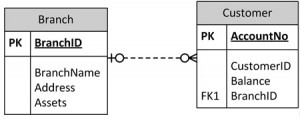
This will ensure that when branch information is added or updated it will only affect one record. When customer information is added or deleted, the Branch information will not be accidently modified or incorrectly recorded.
Source: http://cnx.org/content/m28252/latest/
Another Example:
Employee Project Table
Assumptions: EmpID and ProjectID is a composite PK
Project ID determines Budget. i.e. Project P1 has a budget of 32 hours.
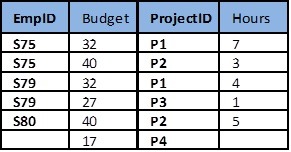
Let’s look at some possible anomalies: Add row {S85,35,P1,9) Problem: Two tuples with conflicting budgets Delete tuple {S79, 27, P3, 1} Problem: Deletes the budget of project P3 Update tuple {S75, 32, P1, 7} to {S75, 35, P1, 7) Problem: Two tuples with different values for project P1’s budget To fix this, we need a table for employees and a table for projects.
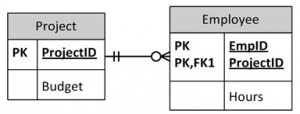
Tables with Data
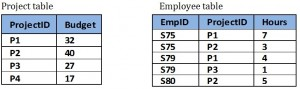
- No anomalies will be created if a budget is changed
- No dummy values are needed for projects that have no employees assigned
- If an employee’s contribution is deleted, no important data is lost
- No anomalies are created if an employee’s contribution is added.
The best approach to creating tables without anomalies is to ensure tables are normalized and that’s accomplished by understanding functional dependencies (FD). FD ensures that all attributes in a table belong to that table. In other words, it will eliminate redundancies and anomalies.
- 8175 reads
