




In the late 1980s and early 1990s the growth of the Internet was causing several operational problems on routers. Many of these routers had a single CPU and up to 1 MByte of RAM to store their operating system, packet buffers and routing tables. Given the rate of allocation of IPv4 prefixes to companies and universities willing to join the Internet, the routing tables where growing very quickly and some feared that all IPv4 prefixes would quickly be allocated. In 1987, a study cited in RFC 1752, estimated that there would be 100,000 networks in the near future. In August 1990, estimates indicated that the class B space would be exhausted by March 1994. Two types of solution were developed to solve this problem. The first short term solution was the introduction of Classless Inter Domain Routing (CIDR). A second short term solution was the Network Address Translation (NAT) mechanism, defined in RFC 1631. NAT allowed multiple hosts to share a single public IP address, it is explained in section Middleboxes.
However, in parallel with these short-term solutions, which have allowed the IPv4 Internet to continue to be usable until now, the Internet Engineering Task Force started to work on developing a replacement for IPv4. This work started with an open call for proposals, outlined in RFC 1550 Several groups responded to this call with proposals for a next generation Internet Protocol (IPng) :
The IETF decided to pursue the development of IPng based on the SIPP proposal. As IP version 5 was already used by the experimental ST-2 protocol defined in RFC 1819, the successor of IP version 4 is IP version 6. The initial IP version 6 defined in RFC 1752 was designed based on the following assumptions :
- IPv6 addresses are encoded as a 128 bits field
- The IPv6 header has a simple format that can easily be parsed by hardware devices
- A host should be able to configure its IPv6 address automatically
- Security must be part of IPv6
When the work on IPng started, it was clear that 32 bits was too small to encode an IPng address and all proposals used longer addresses. However, there were many discussions about the most suitable address length. A first approach, proposed by SIP in RFC 1710, was to use 64 bit addresses. A 64 bits address space was 4 billion times larger than the IPv4 address space and, furthermore, from an implementation perspective, 64 bit CPUs were being considered and 64 bit addresses would naturally fit inside their registers. Another approach was to use an existing address format. This was the TUBA proposal (RFC 1347) that reuses the ISO CLNP 20 bytes addresses. The 20 bytes addresses provided room for growth, but using ISO CLNP was not favored by the IETF partially due to political reasons, despite the fact that mature CLNP implementations were already available. 128 bits appeared to be a reasonable compromise at that time.
IPv6 addressing architecture
The experience of IPv4 revealed that the scalability of a network layer protocol heavily depends on its addressing architecture. The designers of IPv6 spent a lot of effort defining its addressing architecture RFC 3513. All IPv6 addresses are 128 bits wide. This implies that there are 340, 282, 366, 920, 938, 463, 463, 374, 607, 431, 768, 211, 456(3.4 × 1038) different IPv6 addresses. As the sur face of the Earth is about 510,072,000 km2, this implies that there are about 6.67 × 1023 IPv6 addresses per square meter on Earth. Compared to IPv4, which offers only 8 addresses per square kilometer, this is a significant improvement on paper.
IPv6 supports unicast, multicast and anycast addresses. As with IPv4, an IPv6 unicast address is used to identify one datalink-layer interface on a host. If a host has several datalink layer interfaces (e.g. an Ethernet interface and a WiFi interface), then it needs several IPv6 addresses. In general, an IPv6 unicast address is structured as shown in the figure below.
An IPv6 unicast address is composed of three parts :
- A global routing prefix that is assigned to the Internet Service Provider that owns this block of addresses
- A subnet identifier that identifies a customer of the ISP
- An interface identifier that identifies a particular interface on an endsystem
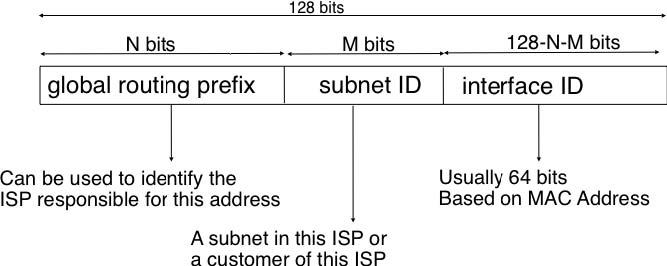
In today’s deployments, interface identifiers are always 64 bits wide. This implies that while there are 2128 different IPv6 addresses, they must be grouped in 264 subnets. This could appear as a waste of resources, however using 64 bits for the host identifier allows IPv6 addresses to be auto-configured and also provides some benefits from a security point of view, as explained in section ICMPv6
It is sometimes necessary to write IPv6 addresses in text format, e.g. when manually configuring addresses or for documentation purposes. The preferred format for writing IPv6 addresses is x:x:x:x:x:x:x:x, where the x ‘s are hexadecimal digits representing the eight 16-bit parts of the address. Here are a few examples of IPv6 addresses :
- ABCD:EF01:2345:6789:ABCD:EF01:2345:6789
- 2001:DB8:0:0:8:800:200C:417A
- FE80:0:0:0:219:E3FF:FED7:1204
IPv6 addresses often contain a long sequence of bits set to 0. In this case, a compact notation has been defined. With this notation, :: is used to indicate one or more groups of 16 bits blocks containing only bits set to 0. For example,
- 2001:DB8:0:0:8:800:200C:417A is represented as 2001:DB8::8:800:200C:417A
- FF01:0:0:0:0:0:0:101 is represented as FF01::101
- 0:0:0:0:0:0:0:1 is represented as ::1
- 0:0:0:0:0:0:0:0 is represented as ::
An IPv6 prefix can be represented as address/length, where length is the length of the prefix in bits. For example, the three notations below correspond to the same IPv6 prefix :
- 2001:0DB8:0000:CD30:0000:0000:0000:0000/60
- 2001:0DB8::CD30:0:0:0:0/60
- 2001:0DB8:0:CD30::/60
In practice, there are several types of IPv6 unicast address. Most of the IPv6 unicast addresses are allocated in blocks under the responsibility of IANA. The current IPv6 allocations are part of the 2000::/3 address block. Regional Internet Registries (RIR) such as RIPE in Europe, ARIN in North-America or AfriNIC in Africa have each received a block of IPv6 addresses that they sub-allocate to Internet Service Providers in their region. The ISPs then sub-allocate addresses to their customers.
When considering the allocation of IPv6 addresses, two types of address allocations are often distinguished. The RIRs allocate provider-independent (PI) addresses. PI addresses are usually allocated to Internet Service Providers and large companies that are connected to at least two different ISPs [CSP2009]. Once a PI address block has been allocated to a company, this company can use its address block with the provider of its choice and change its provider at will. Internet Service Providers allocate provider-aggregatable (PA) address blocks from their own PI address block to their customers. A company that is connected to only one ISP should only use PA addresses.
The drawback of PA addresses is that when a company using a PA address block changes its provider, it needs to change all the addresses that it uses. This can be a nightmare from an operational perspective and many companies are lobbying to obtain PI address blocks even if they are small and connected to a single provider. The typical size of the IPv6 address blocks are:
- /32 for an Internet Service Provider
- /48 for a single company
- /64 for a single user (e.g. a home user connected via ADSL)
- /128 in the rare case when it is known that no more than one endhost will be attached
For the companies that want to use IPv6 without being connected to the IPv6 Internet, RFC 4193 defines the Unique Local Unicast (ULA) addresses (FC00::/7). These ULA addresses play a similar role as the private IPv4 addresses defined in RFC 1918. However, the size of the FC00::/7 address block allows ULA to be much more flexible than private IPv4 addresses.
Furthermore, the IETF has reserved some IPv6 addresses for a special usage. The two most important ones are :
- 0:0:0:0:0:0:0:1 (::1 in compact form) is the IPv6 loopback address. This is the address of a logical interface that is always up and running on IPv6 enabled hosts. This is the equivalent of 127.0.0.1 in IPv4.
- 0:0:0:0:0:0:0:0 (:: in compact form) is the unspecified IPv6 address. This is the IPv6 address that a host can use as source address when trying to acquire an official address.
The last type of unicast IPv6 addresses are the Link Local Unicast addresses. These addresses are part of the FE80::/10 address block and are defined in RFC 4291. Each host can compute its own link local address by concatenating the FE80::/64 prefix with the 64 bits identifier of its interface. Link local addresses can be used when hosts that are attached to the same link (or local area network) need to exchange packets. They are used notably for address discovery and auto-configuration purposes. Their usage is restricted to each link and a router cannot forward a packet whose source or destination address is a link local address. Link local addresses have also been defined for IPv4 RFC 3927. However, the IPv4 link local addresses are only used when a host cannot obtain a regular IPv4 address, e.g. on an isolated LAN.

An important consequence of the IPv6 unicast addressing architecture and the utilisation of link-local addresses is that an IPv6 host has several IPv6 addresses. This implies that an IPv6 stack must be able to handle multiple IPv6 addresses. This was not always the case with IPv4.
RFC 4291 defines a special type of IPv6 anycast address. On a subnetwork having prefix p/n, the IPv6 address whose 128-n low-order bits are set to 0 is the anycast address that corresponds to all routers inside this subnetwork. This anycast address can be used by hosts to quickly send a packet to any of the routers inside their own subnetwork.
Finally, RFC 4291 defines the structure of the IPv6 multicast addresses 1. This structure is depicted in the figure below
The low order 112 bits of an IPv6 multicast address are the group’s identifier. The high order bits are used as a marker to distinguish multicast addresses from unicast addresses. Notably, the 4 bits flag field indicates whether the address is temporary or permanent. Finally, the scope field indicates the boundaries of the forwarding of packets destined to a particular address. A link-local scope indicates that a router should not forward a packet destined to such a multicast address. An organisation local-scope indicates that a packet sent to such a multicast destination address should not leave the organisation. Finally the global scope is intended for multicast groups spanning the global Internet.
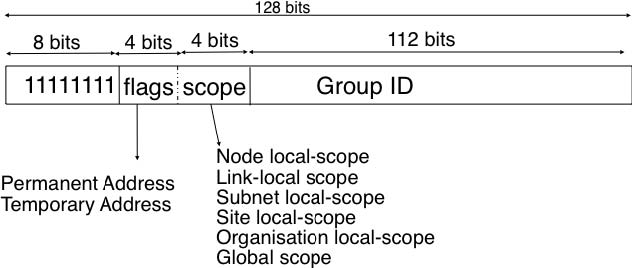
Among these addresses, some are well known. For example, all endsystem automatically belong to the FF02::1 multicast group while all routers automatically belong to the FF02::2 multicast group. We discuss IPv6 multicast later.
IPv6 packet format
The IPv6 packet format was heavily inspired by the packet format proposed for the SIPP protocol in RFC 1710. The standard IPv6 header defined in RFC 2460 occupies 40 bytes and contains 8 different fields, as shown in the figure below.

Apart from the source and destination addresses, the IPv6 header contains the following fields :
- version : a 4 bits field set to 6 and intended to allow IP to evolve in the future if needed
- Traffic class : this 8 bits field plays a similar role as the DS byte in the IPv4 header
- Flow label : this field was initially intended to be used to tag packets belonging to the same flow. However, as of this writing, there is no clear guideline on how this field should be used by hosts and routers
- Payload length : this is the size of the packet payload in bytes. As the length is encoded as a 16 bits field, an IPv6 packet can contain up to 65535 bytes of payload.
- Next Header : this 8 bits field indicates the type 2 of header that follows the IPv6 header. It can be a transport layer header (e.g. 6 for TCP or 17 for UDP) or an IPv6 option. Handling options as a next header allows simplifying the processing of IPv6 packets compared to IPv4.
- Hop Limit : this 8 bits field indicates the number of routers that can forward the packet. It is decremented by one by each router and has the same purpose as the TTL field of the IPv4 header.
In comparison with IPv4, the IPv6 packets are much simpler and easier to process by routers. A first important difference is that there is no checksum inside the IPv6 header. This is mainly because all datalink layers and transport protocols include a checksum or a CRC to protect their frames/segments against transmission errors. Adding a checksum in the IPv6 header would have forced each router to recompute the checksum of all packets, with limited benefit in detecting errors. In practice, an IP checksum allows for catching errors that occur inside routers (e.g. due to memory corruption) before the packet reaches its destination. However, this benefit was found to be too small given the reliability of current memories and the cost of computing the checksum on each router.
A second difference with IPv4 is that the IPv6 header does not support fragmentation and reassembly. Experience with IPv4 has shown that fragmenting packets in routers was costly [KM1995] and the developers of IPv6 have decided that routers would not fragment packets anymore. If a router receives a packet that is too long to be forwarded, the packet is dropped and the router returns an ICMPv6 messages to inform the sender of the problem. The sender can then either fragment the packet or perform Path MTU discovery. In IPv6, packet fragmentation is performed only by the source by using IPv6 options.
The third difference are the IPv6 options, which are simpler and easier to process than the IPv4 options.
Given the size of the IPv6 header, it can cause huge overhead on low bandwidth links, especially when small packets are exchanged such as for Voice over IP applications. In such environments, several techniques can be used to reduce the overhead. A first solution is to use data compression in the datalink layer to compress all the information exchanged [Thomborson1992]. These techniques are similar to the data compression algorithms used in tools such as compress(1) or gzip(1)RFC 1951. They compress streams of bits without taking advantage of the fact that these streams contain IP packets with a known structure. A second solution is to compress the IP and TCP header. These header compression techniques, such as the one defined in RFC 2507take advantage of the redundancy found in successive packets from the same flow to significantly reduce the size of the protocol headers. Another solution is to define a compressed encoding of the IPv6 header that matches the capabilities of the underlying datalink layer RFC 4944.
IPv6 options
In IPv6, each option is considered as one header containing a multiple of 8 bytes to ensure that IPv6 options in a packet are aligned on 64 bit boundaries. IPv6 defines several type of options :
- the hop-by-hop options are options that must be processed by the routers on the packet’s path
- the type 0 routing header, which is similar to the IPv4 loose source routing option
- the fragmentation option, which is used when fragmenting an IPv6 packet
- the destination options
- the security options that allow IPv6 hosts to exchange packets with cryptographic authentication (AH header) or encryption and authentication (ESP header)
RFC 2460 provides lots of detail on the encodings of the different types of options. In this section, we only discus some of them. The reader may consult RFC 2460 for more information about the other options. The first point to note is that each option contains a Next Header field, which indicates the type of header that follows the option. A second point to note is that in order to allow routers to efficiently parse IPv6 packets, the options that must be processed by routers (hop-by-hop options and type 0 routing header) must appear first in the packet. This allows the router to process a packet without being forced to analyse all the packet’s options. A third point to note is that hop-by-hop and destination options are encoded using a type length value format. Furthermore, the type field contains bits that indicate whether a router that does not understand this option should ignore the option or discard the packet. This allows the introduction of new options into the network without forcing all devices to be upgraded to support them at the same time.
Two hop-by-hop options have been defined. RFC 2675 specifies the jumbogram that enables IPv6 to support packets containing a payload larger than 65535 bytes. These jumbo packets have their payload length set to 0 and the jumbogram option contains the packet length as a 32 bits field. Such packets can only be sent from a source to a destination if all the routers on the path support this option. However, as of this writing it does not seem that the jumbogram option has been implemented. The router alert option defined in RFC 2711 is the second example of a hop-by-hop option. The packets that contain this option should be processed in a special way by intermediate routers. This option is used for IP packets that carry Resource Reservation Protocol (RSVP) messages. Its usage is explained later.
The type 0 routing header defined in RFC 2460 is an example of an IPv6 option that must be processed by some routers. This option is encoded as shown below.

The type 0 routing option was intended to allow a host to indicate a loose source route that should be followed by a packet by specifying the addresses of some of the routers that must forward this packet. Unfortunately, further work with this routing header, including an entertaining demonstration with scapy [BE2007] , revealed some severe security problems with this routing header. For this reason, loose source routing with the type 0 routing header has been removed from the IPv6 specification RFC 5095.
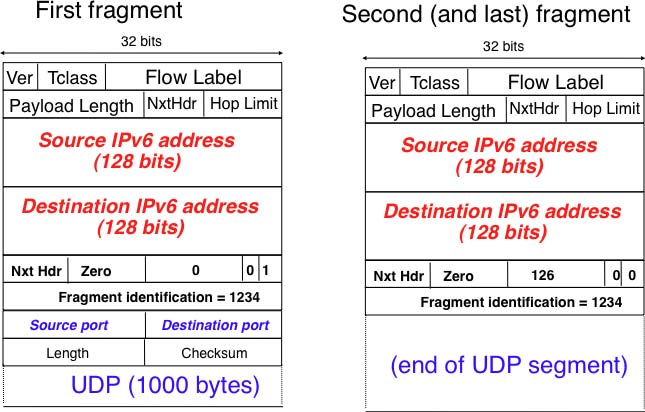
In IPv6, fragmentation is performed exclusively by the source host and relies on the fragmentation header. This 64 bits header is composed of six fields :
- a Next Header field that indicates the type of the header that follows the fragmentation header
- a reserved field set to 0.
- the Fragment Offset is a 13-bit unsigned integer that contains the offset, in 8 bytes units, of the data following this header, relative to the start of the original packet.
- the More flag, which is set to 0 in the last fragment of a packet and to 1 in all other fragments.
- the 32 bits Identification field indicates to which original packet a fragment belongs. When a host sends fragmented packets, it should ensure that it does not reuse the same identification field for packets sent to the same destination during a period of MSL seconds. This is easier with the 32 bits identification used in the IPv6 fragmentation header, than with the 16 bits identification field of the IPv4 header.
Some IPv6 implementations send the fragments of a packet in increasing fragment offset order, starting from the first fragment. Others send the fragments in reverse order, starting from the last fragment. The latter solution can be advantageous for the host that needs to reassemble the fragments, as it can easily allocate the buffer required to reassemble all fragments of the packet upon reception of the last fragment. When a host receives the first fragment of an IPv6 packet, it cannot know a priori the length of the entire IPv6 packet.
The figure below provides an example of a fragmented IPv6 packet containing a UDP segment. The Next Header type reserved for the IPv6 fragmentation option is 44.
Finally, the last type of IPv6 options is the Encaspulating Security Payload (ESP) defined in RFC 4303 and the Authentication Header (AH) defined in RFC 4302. These two headers are used by IPSec RFC 4301. They are discussed in another chapter.
- 3126 reads
