




Null hypothesis testing is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called
the null hypothesis (often symbolized 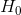 and read as “H-naught”). This is the idea that there is no relationship in the population and that the relationship in the
sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis(often symbolized as
and read as “H-naught”). This is the idea that there is no relationship in the population and that the relationship in the
sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis(often symbolized as 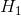 ). This is the idea that there
is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
). This is the idea that there
is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
- Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
- Determine how likely the sample relationship would be if the null hypothesis were true.
- If the sample relationship would be extremely unlikely, then reject the null hypothesis in favor of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis.
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d= 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favor of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value. A low pvalue means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A high pvalue means that the sample result would be likely if the null hypothesis were true and leads to the retention of the null hypothesis. But how low must the pvalue be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called α(alpha)and is almost always set to .05. If there is less than a 5% chance of a result as extreme as the sample result if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant. If there is greater than a 5% chance of a result as extreme as the sample result when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true—only that there is not currently enough evidence to conclude that it is true. Researchers often use the expression “fail to reject the null hypothesis” rather than “retain the null hypothesis,” but they never use the expression “accept the null hypothesis.”
The Misunderstood p Value
The p value is one of the most misunderstood quantities in psychological research (Cohen, 1994). 1 Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the pvalue is the probability that the null hypothesis is true— that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect. The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis weretrue. So a pvalue of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the pvalue is not the probability that any particular hypothesisis true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.
- 5124 reads
