




In statistics, we generally want to study a population. You can think of a population as an entire collection of persons, things, or objects under study. To study the larger population, we select a sample. The idea of sampling is to select a portion (or subset) of the larger population and study that portion (the sample) to gain information about the population. Data are the result of sampling from a population.
Because it takes a lot of time and money to examine an entire population, sampling is a very practical technique. If you wished to compute the overall grade point average at your school, it would make sense to select a sample of students who attend the school. The data collected from the sample would be the students' grade point averages. In presidential elections, opinion poll samples of 1,000 to 2,000 people are taken. The opinion poll is supposed to represent the views of the people in the entire country. Manufacturers of canned carbonated drinks take samples to determine if a 16 ounce can contains 16 ounces of carbonated drink.
From the sample data, we can calculate a statistic. A statistic is a number that is a property of the sample. For example, if we consider one math class to be a sample of the population of all math classes, then the average number of points earned by students in that one math class at the end of the term is an example of a statistic. The statistic is an estimate of a population parameter. A parameter is a number that is a property of the population. Since we considered all math classes to be the population, then the average number of points earned per student over all the math classes is an example of a parameter.
One of the main concerns in the feld of statistics is how accurately a statistic estimates a parameter. The accuracy really depends on how well the sample represents the population. The sample must contain the characteristics of the population in order to be a representative sample. We are interested in both the sample statistic and the population parameter in inferential statistics. In a later chapter, we will use the sample statistic to test the validity of the established population parameter.
A variable, notated by capital letters like X and Y , is a characteristic of interest for each person or thing in a population. Variables may be numerical or categorical. Numerical variables take on values with equal units such as weight in pounds and time in hours. Categorical variables place the person or thing into a category. If we let X equal the number of points earned by one math student at the end of a term, then X is a numerical variable. If we let Y be a person's party afliation, then examples of Y include Republican, Democrat, and Independent. Y is a categorical variable. We could do some math with values of X (calculate the average number of points earned, for example), but it makes no sense to do math with values of Y (calculating an average party afliation makes no sense). Data are the actual values of the variable. They may be numbers or they may be words. Datum is a single value.
Two words that come up often in statistics are mean and proportion. If you were to take three exams in your math classes and obtained
scores of 86, 75, and 92, you calculate your mean score by adding the three exam scores and dividing by three (your mean score would be 84.3 to one decimal place). If, in your math class, there
are 40 students and 22 are men and 18 are women, then the proportion of men students is 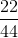 and the proportion of women students is
and the proportion of women students is 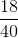 . Mean and proportion are discussed in more detail in later chapters.
. Mean and proportion are discussed in more detail in later chapters.
Example
Define the key terms from the following study: We want to know the average (mean) amount of money first year college students spend at ABC College on school supplies that do not include
books. We randomly survey 100 first year students at the college. Three of those students spent $150, $200, and $225, respectively.
Solution
The population is all first year students attending ABC College this term. The sample could be all students enrolled in one section of a beginning statistics
course at ABC College (although this sample may not represent the entire population).
The parameter is the average (mean) amount of money spent (excluding books) by first year college students at ABC College this term.
The statistic is the average (mean) amount of money spent (excluding books) by first year college students in the sample.
The variable could be the amount of money spent (excluding books) by one first year student. Let X = the amount of money spent
(excluding books) by one first year student attending ABC College.
The data are the dollar amounts spent by the first year students. Examples of the data are $150, $200, and $225.
- 瀏覽次數:4095
