




Shannon's Source Coding Theorem (6.52) has additional applications in data compression. Here, we have a symbolic-valued signal source, like a computer file or an image, that we want to represent with as few bits as possible. Compression schemes that assign symbols to bit sequences are known as lossless if they obey the Source Coding Theorem; they are lossy if they use fewer bits than the alphabet's entropy. Using a lossy compression scheme means that you cannot recover a symbolic-valued signal from its compressed version without incurring some error. You might be wondering why anyone would want to intentionally create errors, but lossy compression schemes are frequently used where the efficiency gained in representing the signal outweighs the significance of the errors.
Shannon's Source Coding Theorem states that symbolic-valued signals require on the average at least H(A) number of bits to represent each of its values, which are symbols drawn from the alphabet A. In the module on the Source Coding Theorem (Source Coding Theorem) we find that using a so-called fixed rate source coder, one that produces a fixed number of bits/symbol, may not be the most efficient way of encoding symbols into bits. What is not discussed there is a procedure for designing an efficient source coder: one guaranteed to produce the fewest bits/symbol on the average. That source coder is not unique, and one approach that does achieve that limit is the Huffman source coding algorithm.
POINT OF INTEREST: In the early years of information theory, the race was on to be the first to find a provably maximally efficient source coding algorithm. The race was won by then MIT graduate student David Huffman in 1954, who worked on the problem as a project in his information theory course. We're pretty sure he received an "A."
- Create a vertical table for the symbols, the best ordering being in decreasing order of probability.
- Form a binary tree to the right of the table. A binary tree always has two branches at each node. Build the tree by merging the two lowest probability symbols at each level, making the
probability of the node equal to the sum of the merged nodes' probabilities. If more than two nodes/symbols share the lowest probability at a given level, pick any two; your choice won't
affect
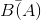
- At each node, label each of the emanating branches with a binary number. The bit sequence obtained from passing from the tree's root to the symbol is its Huffman code.
Example 6.3
The simple four-symbol alphabet used in the Entropy (Entropy) and Source Coding (Source Coding Theorem) modules has a four-symbol alphabet with the following probabilities,
![Pr[a_{0}]=\frac{1}{2}](/system/files/resource/9/9648/9790/media/eqn-img_2.gif)
![Pr[a_{1}]=\frac{1}{4}](/system/files/resource/9/9648/9790/media/eqn-img_3.gif)
![Pr[a_{2}]=\frac{1}{8}](/system/files/resource/9/9648/9790/media/eqn-img_4.gif)
![Pr[a_{3}]=\frac{1}{8}](/system/files/resource/9/9648/9790/media/eqn-img_5.gif)
and an entropy of 1.75 bits (Entropy). This alphabet has the Hufman coding tree shown in Figure 6.18 (Hufman Coding Tree).
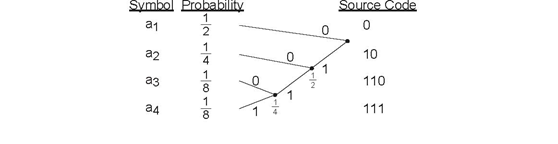
We form a Huffman code for a four-letter alphabet having the indicated probabilities of occurrence. The binary tree created by the algorithm extends to the right, with the root node (the one at which the tree begins) defning the codewords. The bit sequence obtained by traversing the tree from the root to the symbol defines that symbol's binary code.
The code thus obtained is not unique as we could have labeled the branches coming out of each node differently. The average number of bits required to represent this alphabet equals
1.75 bits, which is the Shannon entropy limit for this source alphabet. If we had the symbolic-valued signal s (m)= {a2,a3,a1,a4,a1,a2,... }, our Hufman code would produce the bitstream b (n) = 101100111010 ....
If the alphabet probabilities were different, clearly a different tree, and therefore different code, could well result. Furthermore, we may not be able to achieve the entropy limit. If our
symbols had the probabilities ![Pr[a_{1}]=\frac{1}{2},Pr[a_{2}]=\frac{1}{4},Pr[a_{4}]=\frac{1}{5},Pr[a_{4}]=\frac{1}{20}](/system/files/resource/9/9648/9790/media/eqn-img_6.gif) the average number of bits/symbol resulting from the Huffman coding algorithm would equal 1.75 bits. However, the entropy limit
is 1.68 bits. The Huffman code does satisfy the Source Coding Theorem its average length is within one bit of the alphabet's entropy but you might wonder if a better code existed. David Huffman
showed mathematically that no other code could achieve a shorter average code than his. We can't do better.
the average number of bits/symbol resulting from the Huffman coding algorithm would equal 1.75 bits. However, the entropy limit
is 1.68 bits. The Huffman code does satisfy the Source Coding Theorem its average length is within one bit of the alphabet's entropy but you might wonder if a better code existed. David Huffman
showed mathematically that no other code could achieve a shorter average code than his. We can't do better.
Exercise 6.22.1
Derive the Huffman code for this second set of probabilities, and verify the claimed average code length and alphabet entropy.
- 瀏覽次數:4142
