




前面主要讨论了如何衡量受访者对基本构念中已设计的语句或指标的回答。但是我们怎样设计出这些指标呢?设计这些指标的过程就叫做量表开发。更正式地来说,量表开发也是测量的一部分。对构念的测量需要将与不可观测的构念有关的定性判断与定量的测量单位结合。史蒂文斯(1946)就曾指出,量表开发就是根据一定的规则对客观实体赋值。在实证科学研究中,将抽象概念具体化仍然是最难解决的。
量表开发最终是为得到包含给定构念的衡量语句或者指标的量表。这部分讨论的量表开发和前面部分讨论的量表评价是不同的。量表评价主要是收集受访者对既定量表语句的回答。比如,定类量表收集受访者“是”或者“否”的回答,等距量表收集受访者从“非常不赞同”到“非常赞同”的不同程度的回答。对某一陈述回答进行量表评价并不是量表开发过程。量表开发指的是在量表评价之前开发出量表语句。
量表可能是单维的也可能是多维的,这取决于基本构念是单维的(比如体重,风速,公司规模)还是多维的(比如学术才能,智商等)。单维量表根据由高到低的尺度来衡量构念。需要注意的是,单维量表也可能包含多个语句,但是这些语句都只是衡量同一基本维度。单维量表在社会科学构念衡量中比较普遍。比如"自尊"可通过从高到低的单一维度来衡量。多维量表,运用不同的语句来分别衡量构念的各个维度,或者从不同的维度对构念进行测量,然后加总每个维度的得分得到多维构念的综合衡量得分。比如,学术才能的衡量可通过对学生的数学能力和语言表达能力分别进行衡量来实现,然后对这些得分进行加总得到学术才能的综合得分。由于社会科学研究中大多运用单维量表,接下来,我们将介绍开发单维量表的三种方法。
单维量表开发方法发展于二十世纪上半年代,各种方法根据其发明者进行命名。三种最普遍的单维量表开发方法如下:(1)瑟斯顿的等距量表法、(2)李克特的总加表法和(3)格特曼的累积量表法。三种量表开发方法在很多方面是相似的,只是评判者对量表语句的评级和选择最终量表语句时所运用的统计方法有所区别。接下来我们对每种方法进行讨论。
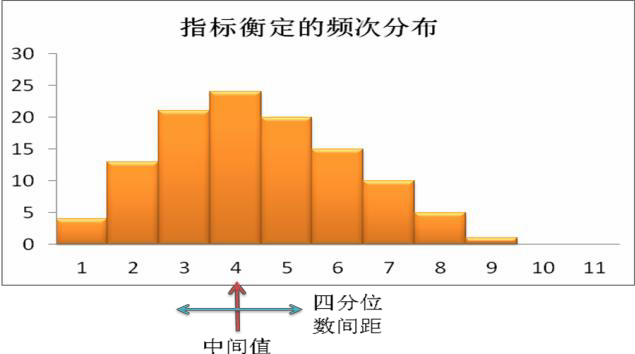
瑟斯顿等距量表法。路易斯·瑟斯顿是最早的最著名的量表开发理论家,他在1925年发明了等距的量表开发方法。这种方法以构念的概念定义为基础,基于概念产生相关量表语句。语句由对构念有所了解的专家进行确定。最初的待选语句用相似的方式进行表述,比如,将其表述成受访者是同意或是反对某一论点(而不是要求受访者对问题进行具体陈述)。接下来,要求相关评判者从待选语句中选出最能反映构念的语句。评判者可以选择在量表构造上受过培训的专业学者,也可以随意选择对该构念有兴趣的调查对象(比如熟悉该现象的调查对象)。在语句选择过程中,评判者根据自身的观点用1到11的值来评判每个语句能够反映该构念的程度(1表示该语句非常不适合代表该构念,11表示该语句很适合代表该构念)。计算出每个语句的中位值和四分位差值(75%分位值和25%分位值的差,可以用来衡量离散程度)描绘成如图表 6.1所示的柱状图。最终选择的语句应有相等的四分位差值。我们可以用每个语句得到的中位值代表语句得分,并选出具有最小的四分位差值的语句。但是,除了完全依靠统计分析方法进行语句选择外,对待选语句的每个层面进行检查并选出最清晰最有意义的表述也不失为一个更好的策略。每个量表语句的中位值代表最后加总所感兴趣的构念的各个语句得分时所运用的权重。这种量表好比一个标尺,每个语句或者陈述根据1到11这一尺度进行评分(同样根据这一尺度进行加权)。因为每个语句得到1到11的评分的概率相同,这种方法就叫做等距法。
瑟斯顿也发明了单维量表开发的其他两种方法:连续区间法和配对比较法。除了评判者评定数据方法的不一样外,这两种方法和等距法的方法基本类似。比如,配对比较方法要求每个评判者对每对陈述进行评价(而不是根据1到11的尺度评价单个陈述),因此取名为配对比较法。由于需要很多配对陈述,这种方法是相当耗时的,而且与等距法相比,其适用度低。
李克特加总量表开发方法。这个单维量表开发方法是由墨菲和李克特(1938)发明的,它很可能是这章介绍的三种量表开发方法中最普遍的方法。和瑟斯顿的量表开发方法一样,李克特的方法是基于感兴趣的构念的定义,利用专家的工作,产生80到100个待选的量表语句。评判者根据1到5的评价尺度对这些语句进行评价(1表示非常不赞同,2表示稍微不赞同,3表示中立态度,4表示稍微赞同,5表示非常赞同)。在这种评价尺度下,最终选出代表构念的语句。这里介绍了几种选择方法:(1)计算评判者所评判的每个语句与总语句(对所有单个语句进行加总)的二元相关系数,剔除相关系数低(如0.6以下)的单个语句。(2)截取最高分数端的25%为高分组,最低分数端的25%为低分组。求出这两个组的平均值,对高低两组的平均值做t检验,选出有较高t值的语句。(即选出高分位组合与低分位组区分度大的语句)。最后,研究人员选出相对有限的语句集,这些语句与总语句的相关系数高或者其语句本身有较大的区分度(即t值较大)。李克特量表开发方法假定所有语句具有相同的权重,因此可以对受访者对于每个语句的回答直接加总评分。因此这种方法叫做加总量表开发。需要注意的是,在加总得分之前,与构念原意义相反的语句应该进行相反方向的赋值(即1代表非常赞同,2代表稍微赞同等等)。
格特曼的累积量表法。这个方法是格特曼根据埃默里·博加德斯的社会距离方法进行设计的。这个方法假设人们和他人一起参加社会活动有不同的意愿,用从“最不强烈的”到“最强烈的”一系列的语句衡量这种意愿程度。这个方法的思想是只要受访者同意其中的一条语句那么代表其也同意先前所有的语句。但在实践中,我们很少能够找到与这种渐增模式相吻合的语句组合。语句组合与渐增内涵的相关程度可以运用量表图分析法检验。
和前面介绍的量表开发方法一样,格特曼量表开发方法也是基于感兴趣的构念的定义并利用专家的工作,产生很多待选的量表语句。评判者对这些语句进行评价,如果这些语句与构念相符,评判者就选择“是”,如果其认为语句与构念不符,他们就选择“否”。接下来,利用矩阵或者表格来表示评判者对待选语句的回答。将表的资料首先依据各被访者回答"是"的个数由上到下进行降序排列,然后再按答案“是”的数目由多至少将各语句从左至右顺序排列。得到重新整理的表格如表格 6.6所示。需要注意的是,量表从左至右(即横穿各个语句)阅读时是渐增的。但是,如表格 6.6所示,存在一些异常情况,因此表格并不完全是渐增的。可以运用量表图分析方法选出最能实现量表渐增特性的语句(当语句数量较少时,可直接通过观察挑选语句)。这种统计方法评估每个语句的得分,并利用各个语句的得分加总计算得出全部语句的分值。
| 回答者 | 语句12 | 语句5 | 语句3 | 语句22 | 语句8 | 语句7 | … |
| 29 | Y | Y | Y | Y | Y | Y | |
| 7 | Y | Y | Y | - | Y | - | |
| 15 | Y | Y | Y | Y | - | - | |
| 3 | Y | Y | Y | Y | - | - | |
| 32 | Y | Y | Y | - | - | - | |
| 4 | Y | Y | - | Y | - | - | |
| 5 | Y | Y | - | - | - | - | |
| 23 | Y | Y | - | - | - | - | |
| 11 | Y | - | - | Y | - | - | |
| Y 表示妨碍矩阵累积性的异常情况 | |||||||
- 瀏覽次數:13297
