




信度是指在多大程度上对某个构念的测量是一致的或可靠的。换句话说,如果我们用这个量表多次测量相同的构念,在潜在现象没有发生变化的情况下,我们是否每次都能得出相同的结果?不可靠测量的一个例子是让别人猜你的体重。人们的猜测很可能是不同的,不同的测量将会不一致,因此,通过“猜测”来进行测量是不可靠的。一个更可靠的测量是使用体重表,这样除非你的体重在测量间隔期发生了实际的变化,否则你每次踏上体重计都有可能得到相同的数值。
注意,信度是指一致性而不是精确性。前例中的体重计,如果体重计校准错了(比如,为了使你感觉较好,从你真实的体重中减去10磅),这将无法衡量你的真实体重,因此这不是一个有效的测量。然而,校准错误的体重计在每次称量时都会给出相同的重量(比真实重量少10磅),因此该量表是可靠的。
社会科学计量中不可靠观测的来源是什么?观测者(或研究者)的主观性是主要来源之一。如果公司的员工士气用观察员工是否互相微笑、是否开玩笑等等来衡量,若观测者在非常繁忙的工作日(没时间开玩笑、交谈)或是在非常轻松的工作日(有更多交谈和玩笑的时间)观察员工,那么不同的观测者对士气水平有不同的推测。即使在同一天,两个观测者对士气水平形成不同的推测,这取决于他们认为什么是笑话、什么不是笑话。“观测”是一个定性的测量手段。有时,运用定量测量可以提高可靠性。例如,通过计算一个月内提出不满的次数来衡量(逆)士气。当然,无论不满是否是一个有效测量,它更少受制于人类的主观性,因此更可靠。第二个不可靠观测的来源是提出不准确、含糊不清的问题。例如,如果询问人们的工资是多少,不同的人对这个问题有不同的理解:月薪、年薪、或每小时的工资,因此,导致结果可能会大不相同并且不可靠。不可靠的第三个来源是提出的问题是受访者不熟悉或不关心的问题,如问一个美国大学毕业生对斯洛文尼亚和加拿大的关系是否满意,或者要求公司的首席执行官评价公司技术策略的有效性——而他很可能将技术策略委派给技术主管。
那么如何才能创造可靠的测量呢?正如许多社会科学研究一样,如果测量需要向其他人征集信息,那么就可以从替换数据收集方式开始,即用主观性低的方法(如问卷)替代主观性高的方法(如观察);只询问受访者知道答案的问题或他们关心的事件;在测量时避免模糊不清的指标(即清楚地界定收集的信息是否是年薪);简化指标的措辞确保受访者不会错误理解(即避免使用受访者不理解的复杂文字)。这些措施即使不会使测量完全可靠,也会提高我们测量的可靠性。尽管如此还是需要对测量指标的可靠性进行检测。有很多种方法可以评估信度,下面将讨论这个问题。
评判间信度。评判间信度,也称为观测者间信度,是对两个或两个以上独立评判(观测者)关于同一构念一致性的测量。通常在试验研究中对此进行评估,并且根据构念的测量类型可采用两种方式来实现。如果测量是分类的,而且对所有类别都进行了界定,评判核查每个观察落在哪一类,评判间一致性的比例可作为评判间信度的估值。例如,如果两个评判将100个观测分到三种可能类别中的一类中,他们分类的重合度为75%,那么评判间信度是0.75。如果这种方法是测量区间或是比例(例如,两个评判每隔5分钟用1-7级的量表测量课堂活动),两个评价者衡量之间简单的相关也可用来评估评判间信度。
重测信度。重测信度衡量了不同时点对相同样本的同一构念进行两次测试的一致性。如果观测在两次测试间没有发生实质的变化,这种测量是可靠的。两次测验得到的观察值的相关系数是重测信度的估计。这里指出两次测试的时间间隔是至关重要的。一般来说,时间间隔越长,这段时间内(由于随机误差)两个观察值发生变化的可能性越大。
分半信度。分半信度是构念测量的两个一半之间一致性的衡量。例如,如果对一个构念有一个10个指标的测量,首先,将这10个项目随机等分为两组(如果整个数字是奇数可以不等分),并且在相同的受访者中实施测试。然后,计算出每个受访者在每组测试中的总分,每组之间的相关系数作为分半信度的衡量。指标越多,每组测量的相似性越大(因为随着更多指标的加入误差降低了),因此,该技术倾向于系统性地低估长量表的信度。
内部一致信度。内部一致信度是对同一构念不同测量指标一致性的衡量。如果对受访者采用一个多指标量表,那么受访者在多大程度上采用相似的方式来评价这些指标反映了内部一致性。该信度可以用指标间的相关系数均值、单个指标与总体指标间的相关系数均值、或更普遍地用Cronbach’s α来估计。例如,如果有一个包含六个指标的量表,那么,将有十五种不同的指标配对方式,即这六个指标之间的十五个相关系数。指标间相关系数均值是这十五个相关系数的平均数。为计算单个指标与总体指标的相关系数均值,首先应对六个项目赋值创建一个“总体”指标,然后计算每个指标与总体指标的相关系数,最后再计算这六个相关系数的均值。上述两种测量都没有考虑测量指标的个数(在这个例子中是六个指标)。李·克隆巴赫在1951年提出了信度测量——Cronbach’s α,该指标在信度估计时注重量表规模,用以下的公式计算:
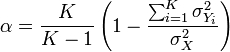
K是测量指标的数量,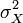 是观测到的总评分的方差(标准差的平方),
是观测到的总评分的方差(标准差的平方),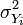 是观察指标i的方差。
是观察指标i的方差。
标准化的Cronbach’sα可以用一个简单公式计算:
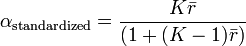
K是指标的的数量,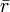 是指标间相关系数的均值,即矩阵的上三角(或下三角)K(K-1)/2个系数的均值。
是指标间相关系数的均值,即矩阵的上三角(或下三角)K(K-1)/2个系数的均值。
- 6816 reads
