




Many researchers now report how unusual the sample t-score would be if the null hypothesis was true rather than choosing an α and stating whether the sample t-score implies the data supports one or the other of the hypotheses based on that α. When a researcher does this, he is essentially letting the reader of his report decide how much risk to take of making which kind of mistake. There are even two ways to do this. If you look at the portion of the t-table reproduced above, you will see that it is not set up very well for this purpose; if you wanted to be able to find out what part of a t-distribution was above any t-score, you would need a table that listed many more t-scores. Since the t-distribution varies as the df changes, you would really need a whole series of t-tables, one for each df.
The old-fashioned way of making the reader decide how much of which risk to take is to not state an α in the body of your report, but only give the sample t-score in the main text. To give the
reader some guidance, you look at the usual t-table and find the smallest 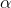 , say it is .01, that has a t-value less than the one you computed for the sample. Then write a footnote saying "the data supports
the alternative hypothesis for any
, say it is .01, that has a t-value less than the one you computed for the sample. Then write a footnote saying "the data supports
the alternative hypothesis for any 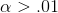 ".
".
The more modern way uses the capability of a computer to store lots of data. Many statistical software packages store a set α detailed t-tables, and when a t-score is computed, the package has
the computer look up exactly what proportion of samples would have t-scores larger than the one for your sample. Table 5.1 Output from typical statistical software for LaTonya's problem shows the computer output for LaTonya's problem from a typical statistical package. Notice that the
program gets the same t-score that LaTonya did, it just goes to more decimal places. Also notice that it shows something called the "P value". The P value is the proportion of t-scores that are
larger then the one just computed. Looking at the example, the computed t statistic is 1.41188 and the P value is 0.1038. This means that if there are 6 df, a little over 10 per cent of samples
will have a t-score greater than 1.41188. Remember that LaTonya used an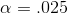 and decided that the data supported H0 :, the P value of .1038 means that H0 : would be
supported for any α less than .1038. Since LaTonya had used
and decided that the data supported H0 :, the P value of .1038 means that H0 : would be
supported for any α less than .1038. Since LaTonya had used 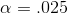 ,
this p value means she does not find support for H0 :.
,
this p value means she does not find support for H0 :.
|
Hypothesis test: Mean |
|
Null Hypothesis: Mean = 8.71 Alternative: greater than Computed t statistic = 1.41188 P value = 0.1038 |
The P-value approach is becoming the preferred way to The P-value presents research results to audiences of professional researchers. Most of the statistical research conducted for a business firm will be used directly for decision making or presented to an audience of executives to aid them in making a decision. These audiences will generally not be interested in deciding for themselves which hypothesis the data supports. When you are making a presentation of results to your boss, you will want to simply state which hypothesis the evidence supports. You may decide by using either the traditional α approach or the more modern P-value approach, but deciding what the evidence says is probably your job.
- 1658 reads
