




To describe the location of a distribution, statisticians use a "typical" value from the distribution. There are a number of different ways to find the typical value, but by far the most used is the "arithmetic mean", usually simply called the "mean". You already know how to find the arithmetic mean, you are just used to calling it the "average". Statisticians use average more generally—the arithmetic mean is one of a number of different averages. Look at the formula for the arithmetic mean:
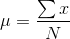
All you do is add up all of the members of the population, 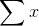 , and
divide by how many members there are, N. The only trick is to remember that if there is more than one member of the population with a certain value, add that value once for every member that
has it. To reflect this, the equation for the mean sometimes is written:
, and
divide by how many members there are, N. The only trick is to remember that if there is more than one member of the population with a certain value, add that value once for every member that
has it. To reflect this, the equation for the mean sometimes is written:
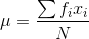
where 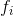 is the frequency of members of the population with the value
is the frequency of members of the population with the value
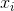 .
.
This is really the same formula as above. If there are seven members with a value of ten, the first formula would have you add seven ten times. The second formula simply has you multiply seven by ten—the same thing as adding together ten sevens.
Other measures of location are the median and the mode. The median is the value of the member of the population that is in the middle when the members are sorted from smallest to largest. Half of the members of the population have values higher than the median, and half have values lower. The median is a better measure of location if there are one or two members of the population that are a lot larger (or a lot smaller) than all the rest. Such extreme values can make the mean a poor measure of location, while they have little effect on the median. If there are an odd number of members of the population, there is no problem finding which member has the median value. If there are an even number of members of the population, then there is no single member in the middle. In that case, just average together the values of the two members that share the middle.
The third common measure of location is the mode. If you have arranged the population into a frequency or relative frequency distribution, the mode is easy to find because it is the value that occurs most often. While in some sense, the mode is really the most typical member of the population, it is often not very near the middle of the population. You can also have multiple modes. I am sure you have heard someone say that "it was a bimodal distribution". That simply means that there were two modes, two values that occurred equally most often.
If you think about it, you should not be surprised to learn that for bell-shaped distributions, the mean, median, and mode will be equal. Most of what statisticians do with the describing or inferring the location of a population is done with the mean. Another thing to think about is using a spreadsheet program, like Microsoft Excel when arranging data into a frequency distribution or when finding the median or mode. By using the sort and distribution commands in 1-2-3, or similar commands in Excel, data can quickly be arranged in order or placed into value classes and the number in each class found. Excel also has a function, =AVERAGE(...), for finding the arithmetic mean. You can also have the spreadsheet program draw your frequency or relative frequency distribution.
One of the reasons that the arithmetic mean is the most used measure of location is because the mean of a sample is an "unbiased estimator" of the population mean. Because the sample mean is an unbiased estimator of the population mean, the sample mean is a good way to make an inference about the population mean. If you have a sample from a population, and you want to guess what the mean of that population is, you can legitimately guess that the population mean is equal to the mean of your sample. This is a legitimate way to make this inference because the mean of all the sample means equals the mean of the population, so, if you used this method many times to infer the population mean, on average you'd be correct.
All of these measures of location can be found for samples as well as populations, using the same formulas. Generally, 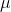 is used for a population mean, and
is used for a population mean, and 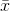 is used for sample means. Upper-case N, really a Greek "nu", is used for the size of a population, while lower case n is used for
sample size. Though it is not universal, statisticians tend to use the Greek alphabet for population characteristics and the Roman alphabet for sample characteristics.
is used for sample means. Upper-case N, really a Greek "nu", is used for the size of a population, while lower case n is used for
sample size. Though it is not universal, statisticians tend to use the Greek alphabet for population characteristics and the Roman alphabet for sample characteristics.
- 1526 reads
