




Nowadays, one of the main problems with e-learning systems is the accessibility, interoperability, durability and reusability of the educational materials. It is necessary that the platforms of e-learning and the author tools are based on standards and specifications and, in addition, all the learning objects are "described" using the same "language". Moreover, it is sure that a learning object will be re-usable, if it is created according to the definition of some standard, and so, the object content must be described through metadata. However, the standards do not provide any guideline of how a learning object can be discovered.
Therefore, the educational content should be:
- Developed as standards.
- Universally discovered.
- Easy to find. Independent of metadata format.
- Reusable.
- Independent of the storage platform.
- Integrated in other learning systems.
E-learning systems have made satisfactory progress towards communication through the Internet, either to communicate with users or to intercommunicate with others systems. The main feature of the new e-learning environment is the use of the Web as a single distribution platform. Therefore, e-learning systems provide features which were unknown in the traditional education system, making it possible to solve some deficiencies as the high production and development time costs. However, there is no reusability of the learning objects and software components that compose an e-learning tool.
These problems are summarized by (Koper, 2000) on the following points:
- The increase of the heterogeneous products and the interaction between people and systems, only between people or only between systems.
- The spectacular increase of available information and its dispersion in different systems and applications, which implies the need to communicate the different software products and platforms.
- The distributed e-learning process organization, due to geographic dispersion of the course members.
Therefore, there are different solutions to solve these problems; solutions that try to unify the educational way of creation and the way of integrating platforms and educational repositories, and also the communication of those contents. The solution to these problems is called interoperability.
The IEEE defines interoperability as the ability of two or more systems or components to exchange information and to use the information exchanged. Within the world of e-learning exists a set of standards and specifications (hereinafter “norms”) to ensure interoperability between different learning systems and more specifically those related with learning object repositories (Otón S. et al, 2009). These norms enable the exchange of the teaching contents they store and consequently achieve the reuse of those contents in different training projects.
These norms may be classified as follows:
1.Norms geared towards building and defining the learning object itself, that is to say, its content and metadata.
2. Norms geared towards the publication and search for learning objects by making it easier to locate resources in different repositories.
3. Norms designed to assist in the design of repositories whose aim is interoperability and which therefore specify software architecture for their construction.
The majority of the norms belonging to the second and third groups norms are based on Web services and service-oriented architecture (SOA) (W3C, 2004). Web services constitute a reusability mechanism of distributed software components. They can be registered and published in the Web, and they make use of open and standard protocols of Internet, like HTTP, XML, UDDI, SOAP, WSDL and REST, that deal with the interoperability problem among the different technologies and software platforms.
The first group of norms are aimed at the generation, documentation and packaging of learning objects. Its main feature is the description of the object using metadata. The main norm to comply in the description of the metadata of a learning object is LOM (IEEE, 2002). With respect to packaging, we outline the two most used norms today that are SCORM (ADL, 2002) and IMS Common Cartridge (IMS CC, 2008) belonging to a broader standard called Digital Learning Services Standards.
The IMS Common Cartridge (CC) specification proposes a standard way of packaging learning objects and its metadata (making use of the LOM specification). This standard describes the structure of a package, disposing learning resources as a folder tree. Assessments, Question Banks, Discussion Topics, Web content, and many others can be packaged inside a CC cartridge.
CC considers four categories of resources inside a package:
- imsmanifest.xml: A file describing the content of the package. It must be placed at the root directory in the package.
- Web Content: A folder tree which contains digital content resources (Web pages, documents, media files, etc.), Web links and links to other resources inside the package.
- All resources inside this category must be placed at the Web Content root folder or at one of its subfolders. Only one single Web Content folder can exist inside a package.
- Learning Application Object (LAO): A folder tree with the files (or file references) needed for a learning system to distribute learning object contents. There can be multiple LAOs folders inside a package and each one can contain subfolders.
- Folder: A package may contain folders to group other kinds of resources not considered in the categories defined above.
References between the resources packaged in a cartridge can exist with the following restrictions:
- A Web content resource can reference any other Web content resource, but it can’t reference resources outside the Web content folder.
- A LAO resource can reference Web content resources and any other LAO resource inside its folder tree, but it can’t reference LAOs outside its folder tree.
One of the basic pillars of interoperability between learning object repositories is the ability to search their contents. Recently, search systems have evolved from only working in one repository to working simultaneously in various distributed repositories; this is known as “federated search”. In this kind of search is widespread to use of Web services, so that these services act as intermediaries between different learning objects repository. A proof of this is found in the specification SQI (CEN, 2005). Examples of repositories that implement federated search through SQI can be found in Merlot, Ariadne or GLOBE.
SQI was defined by the CEN (European Committee for Standardization). It forms part of a public initiative known as the CEN/ISSS Learning Technologies Workshop, whose commitment it is to guarantee interoperability between learning object repositories. SQI uses XML as the language for receiving information requests and for returning the results. SQI specification consists in a definition of a set of methods that a repository should provide, so that remote systems (clients) can query for learning objects stored within the repository. (Figure 13.2) shows how repository A (origin) makes a data request from repository B (destination). For this communication to be possible, it is necessary to use a common query language (based on SQI) which both repositories understand. However, the internal query language of each repository may differ. In this case, a layer (an SQI component) is responsible for making the necessary conversions.
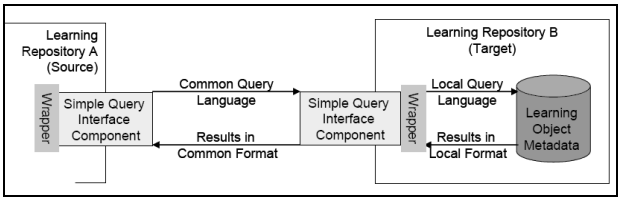
SQI identifies thirteen methods to be provided by such systems, these methods are embedded in a Web service that is exposed by the target repository and defined in WSDL files. They are classified in four categories: configuration methods, session management methods and query methods (synchronous and asynchronous).
SPI (Simple Publishing Interface) specification (CEN, 2010), also devised by the CEN, is a protocol for publishing digital objects or their metadata in repositories. It provides a simple protocol which is easy to implement and integrate in already existing systems. His objective is to develop a practical approach towards interoperability between repositories.
SPI makes a distinction between semantic and syntactic interoperability. Syntactic interoperability is the ability of applications to deal with the structure and format of data (for example XML documents). Semantic interoperability refers to the ability of two parties to agree on the meaning of data or methods. When exchanging data, semantic interoperability is achieved when data is interpreted in the same way by all the applications involved.
In a typical SPI scenario, two approaches allow for passing data from a source to a target: “by value” or “by reference”. “By value” publishing embeds a learning object, after encoding, into the message that is sent to a target. “By reference” publishing embeds a reference (e.g., a URL) to a learning object to publish into the message that is sent to a target. The model for SPI builds on a separation between data and metadata, the data is a resource (e.g., a learning object) and the metadata is the description of the resource (e.g., using LOM to describe the learning object) (Figure 13.3). Every resource can be described by zero, one, or more metadata instances. A metadata instance must have a metadata identifier that identifies the metadata instance itself, and must have a resource identifier that is equal to the identifier of the resource. The metadata identifier enables distinguishing between multiple metadata instances referring to the same resource. In this model, a metadata instance must be connected to a resource; however the resource may be hosted externally.
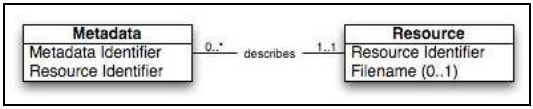
The SPI model defines several classes of messages and functional units in a publishing architecture. When binding the specification to a given technology, these concepts are mapped into a concrete specification that can be implemented in a repository and for which conformance can be tested.
SPI defines the following methods:
- Submit/Delete Metadata Record: These are methods for inserting or deleting object descriptions respectively.
- Submit/Delete Resource by value / by reference: These are methods for inserting or deleting resources respectively.
- The SPI model does not include explicit methods for updating resources or metadata instances.
The IMS has also specified a set of services addressed to exchange of information that describes people, groups, memberships, courses and outcomes within the context of learning. That is the IMS Learning Information Services (LIS) specification (IMS LIS, 2010). LIS consists of six services that can either be used individually or in various combinations.
To achieve interoperability across Service Oriented Architectures, IMS has developed the General Web Services (GWS) specification (IMS GWS, 2005). The specification is formed by different profiles focused on addressing, security, attachments and a base profile describing most common problems when Web Services are used. The specification offers solutions to improve those considered by WS-I specifications. LIS is aimed at classic Web Services, i.e., SOAP based Web Services. Other kinds of Web Services such as RESTful Web Services are out of scope.
There is a necessity to create, manage, organize and exchange resource lists (collections of resources and their metadata instances) in distributed learning architectures. IMS Resource Lists Interoperability (RLI) exposes a flexible model (IMS RLI, 2004) that enables resource lists handling between systems that comply with the specification.
In order to exchange vocabulary between the parts of a learning system, the IMS Vocabulary Definitions Exchange (VDEX) defines a grammar for the exchange vocabulary lists (IMS VDEX, 2004). These lists are formed by domain values that are understood by systems involved in the learning architecture.
The IMS Learning Object Discovery and Exchange (LODE) charter (IMS LODE, 2008) is aproposal to achieve easily discoverable and exchangeable learning objects stored in digital repositories. The draft, rather than specify a model, compiles a set of use cases and scenarios which are inside the scope of the research. LODE is focused on Search, Publication, Query and Metadata. Many of the scenarios considered by LODE are solved in existingspecifications, so the final specification of LODE could look like a framework combining e-learning standards to perform discovery and exchange between heterogeneous repositories. Finally it shall be noted that service-oriented architectures (SOA) are starting to be used massively for building e-learning systems and learning object repositories. We may find a number of interesting norms for the design of these systems to ensure interoperability and to be defined as the architectures of computer systems that support them. The most interesting is IMS Abstract Framework (AF), a framework that covers the entire range of possible e-learning architectures that could be constructed from a set of services based on SOA. It focuses on support for distributed training systems and one of its principles is interoperability. It is also interesting to read “Adoption of Service Oriented Architecture for Enterprise Systems in Education: Recommended Practices” from IMS.
On the other hand we find CORDRA which is one of the most detailed architectures. As an open, standard-based model, it allows to design software systems which are intended for the discovery, sharing and reuse of teaching material through interoperable repositories. Since Ariadne, an architecture has been proposed for repositories which implement SQI-based federated searches.
- 2629 reads
