




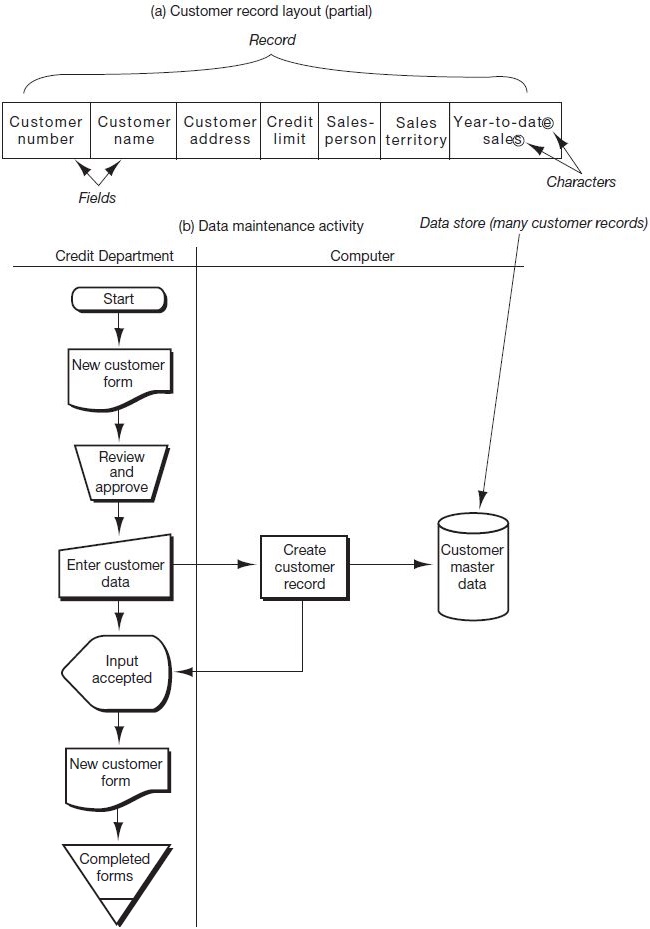
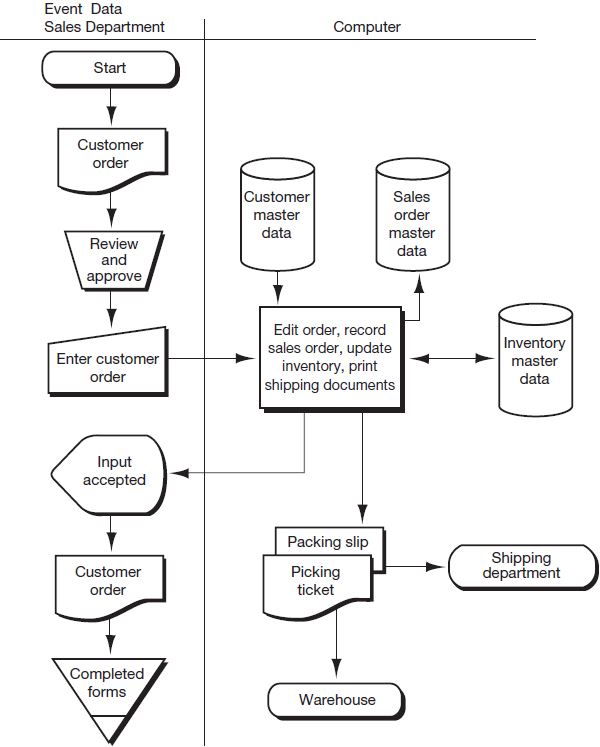
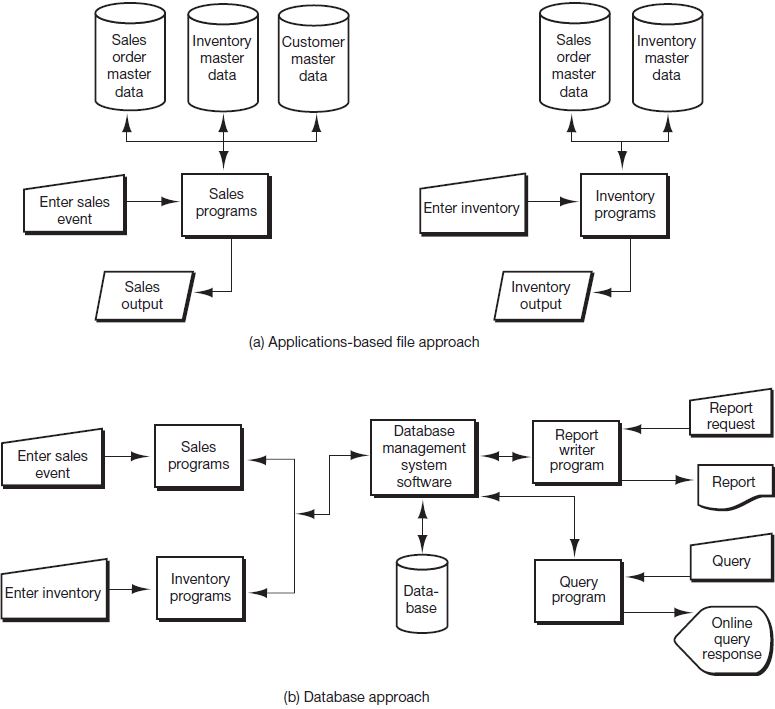
In Figure 3.5 we compare and contrast the applications-based file approach found in a transaction processing system (discussed in this section) with the database approach to data management (discussed in the following section). Figure 3.6 contains the record layouts for the files in Figure 3.5, part (a).
Prior to the development of database concepts, companies tended to view data as a necessary adjunct of the program or process that used the data. As shown in part (a) of Figure 3.5, this view of data, based on the transaction processing approach to file management, concentrates on the process being performed; therefore, the data play a secondary or supportive role in each application system. Under this approach, each application collects and manages its own data, generally in dedicated, separate, physically distinguishable files for each application. For example, Figure 3.3, part (b) and 3.4 assumed a “transaction-centric” approach to file management. One outgrowth of this approach is the data redundancy that occurs among various files. For example, notice the redundancies (indicated by double-ended arrows) depicted in the record layouts in Figure 3.6. Data redundancy often leads to inconsistencies among the same data in different files and increases the storage cost associated with multiple versions of the same data. In addition, data residing in separate files are not shareable among applications. Now let’s examine how some of these redundancies might come about.
The data represented in Figure 3.6 have two purposes. The data (1) mirror and monitor the business operations (the horizontal information flows) and (2) provide the basis for managerial decisions (the vertical information flows).2 In addition to data derived from the horizontal flows, managers use information unrelated to event data processing. These data would be collected and stored with the business event related data. Let’s look at a few examples to tie this discussion together.
Suppose that the sales application wished to perform sales analysis, such as product sales by territory, by customer, or by salesperson. To do so, the sales application would store data for sales territory and salesperson in the sales order record shown in part (a) of Figure 3.6. But, what if the inventory application wanted to perform similar analyses? To do so, the inventory application would store similar, redundant data about territory and salesperson as depicted in part (b) of Figure 3.6. As implied by Figure 3.5, part (a), the sales data in the inventory data file—including customer territory and salesperson—could be updated by the sales application or updated separately by the inventory application. As a second example, what if the sales application wanted to know very quickly the amount of sales for a customer? Then, the summary data on the customer master data file (year-to-date sales) could be stored as shown in part (c) of Figure 3.6. Alternatively, the information could be obtained as needed by summarizing data on the sales order or in the inventory data.
As a final sales example, let’s assume we would like to know all the products that a particular customer buys (perhaps so we can promote those products the customer is not buying). Given the record layouts depicted in Figure 3.6, we could obtain that information by sorting the inventory or sales order data by customer number. Alternatively, we could have collected these data in the customer master data store! In either case, the data are difficult and expensive to obtain. And, if the applications were not originally designed to give us these data, this approach to file management makes it quite difficult to add this access after the fact.
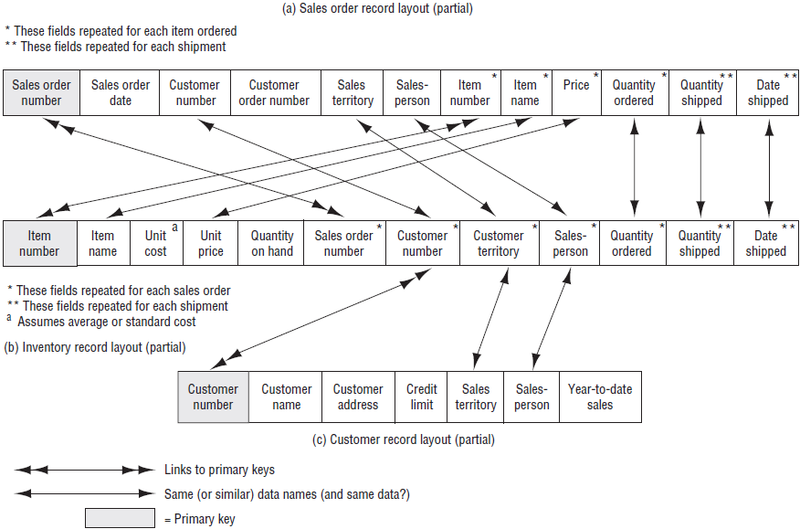
We could provide several more examples from inventory, but by now we trust that we have made our point. All of these examples consist of business event data related to the selling of merchandise. The transaction processing approach leaves us with similar problems for standing data. Note in Figure 3.6 the redundancies among the three data files with respect to standing data such as customer number, territory, and salesperson. Could these redundant fields become inconsistent? Again, we would have to say yes. The database approach to data management solves many of these problems. We will return to Figure 3.6 and describe what these data might look like with a database, rather than separate application files.
- 9722 reads
