




As we mentioned earlier, there is a three-step strategy to identify the relationships that should be included in a data model. First, it is very important that you study business events, and understand users’ information requirements, in order to identify all of the ways in which different entities are related. This information will provide the foundation level of relationships required in the database model. The remaining two steps (i.e., evaluating each of the entities in pairs to determine if any entity provides an improvement in describing an attribute contained in the other entity, and evaluating each entity to determine if there would be any need for two occurrences of the same entity to be linked) enable you to refine and improve this foundation-level model.
The focus for our E-R model development will be on the client billing process generally used by service firms such as architecture, consulting, and legal firms. The nature of the process is that each employee in the firm keeps track of time spent working on each client’s service, generally filling out a time sheet each week. The hours spent on a client are then multiplied by that employee’s billable rate for each hour worked. The cumulative fees for all employees’ work are used to generate the bill for the client. This way, the client only pays for the services it actually receives. The challenge here is capturing all of the information necessary to track employees’ work hours and client billing information.
Examine Figure 3.11, part (a). Desirable linkages between entities will often be fairly easy to recognize when the relationship appears to define an attribute more clearly. If our billing system requires that we know for which client an employee has worked, the entity representing work completed needs to include a client number. This client number would link the WORK_COMPLETED entity to the CLIENT entity that provides us with a full description of the attribute denoted by client number in WORK_COMPLETED. Obviously, as shown in Figure 3.11, part (a), CLIENT is a separate entity and not an attribute. At the same time, CLIENT does improve the description of an attribute for the work completed—the client for whom the work was performed. This descriptive value makes it apparent there should be a relationship between the CLIENT entity and the entity capturing the completed work. Hence, we can often identify the need for defining relationships (such as Works_For) by also looking at the prescribed entities as pairs (in this case, we jointly examined the pair CLIENT and WORK_COMPLETED) to identify logical linkages that would improve the description of an entity’s attributes.
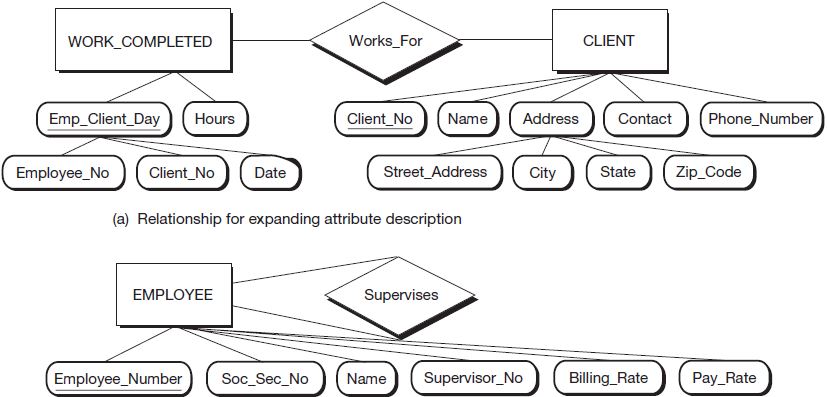
Let’s look at another type of relationship that is displayed in Figure 3.11, part (b). The relationship Supervises is referred to as a recursive relationship. A recursive relationship is a relationship between two different entities of the same entity type. For instance, there usually are relationships between two employees, such as one employee who supervises another employee. This relationship may be important in some decision-making contexts and, therefore, should be represented in our database. We represent this relationship using the technique demonstrated in Figure 3.11, part (b). Consider the alternative: If we try to represent supervisors and their supervised employees as separate entities in our model, we end up with data redundancies when the supervisor is in fact supervised by a third employee. It is easier simply to create a recursive relationship to the entity, EMPLOYEE, whereby a link is created between one employee who is being supervised and another employee who is the supervisor. As shown in our sample diagram, the diamond is still used to represent the recursive relationship, Supervises, just as would be used to show any relationship (e.g., Works_For in part a).
|
Review Question What is different about a recursive relationship in comparison to other relationship in a data model? |
- 4446 reads
