





|
The IS function must see that IT services continue to be provided at the levels expected by the users. To do so, they must provide a secure operating environment for IT and plan for increases in required capacity and potential losses of usable resources. To ensure that sufficient IT resources remain available, management should establish a process to monitor the capacity and performance of all IT resources. For example, the actual activity on an organization’s Web site must be measured and additional capacity added as needed. To ensure that IT assets are not lost, altered, or used without authorization, management should establish a process to account for all IT components, including applications, technology, and facilities, and to prevent use of unauthorized assets. To ensure that IT resources remains available, processes should be in place to identify, track, and resolve in a timely manner problems and incidents that occur. Three important aspects of the IT processes designed to address these issues are discussed below: ensuring continuous service, restricting access to computing resources, and ensuring physical security. |
Ensure Continuous Service
To ensure that sufficient IT resources continue to be available for use in the event of a service disruption, management should establish a process, coordinated with the overall business continuity strategy, that includes disaster recovery/contingency planning for all IT resources and related business resources, both internal and external. These control plans are directed at potential calamitous losses of resources or disruptions of operations—for both the organization and its business partners. Catastrophic events, such as those experienced on September 11, 2001, have resulted in a heightened awareness of the importance of these controls. The types of backup and recovery covered in this section have been referred to in a variety of ways, including but not limited to: disaster recovery planning, contingency planning, business interruption planning, and business continuity planning.Regardless of the label, these controls must include a heavy dose of pre-loss planning that will reasonably ensure post-loss recovery.
| Activity | Discussion |
| Define service levels | To ensure that internal and third party IT services are effectively delivered, service level requirements must be defined. Service levels are the organizational requirements for the minimum levels of the quantity and quality of IT services. |
| Manage third-party services | To ensure that IT services delivered by third parties continue to satisfy organizational requirements, processes must be in place to identify, manage, and monitor outsourced IT resources. |
| Manage IT operations | To ensure that important IT functions are performed regularly and in an orderly fashion, the information services function should establish and document standard procedures for IT operations. |
| Manage data |
To ensure that data remain complete, accurate, and valid, management should establish a combination of process and general controls. Process controls
relate directly to the data as it is being processed. General controls ensure data integrity once the data have been processed and include production backup and
recovery control plans that address short-term disruptions to IT operations. Production backup and recovery starts with making a copy (i.e., a backup) of data files (or the database), programs, and documentation. The copies are then used for day-to-day operations, and the originals are stored in a safe place. Should any of the working copies be damaged or completely destroyed, the originals are retrieved (i.e., the recovery) from safekeeping. |
| Identify and allocate costs | To ensure that IT resources are delivered in a cost-effective manner and that they are used wisely, information services management should identify the costs of providing IT services and should allocate those costs to the users of those services. |
Before we go further, let us note that contingency planning extends much beyond the mere backup and recovery of stored computer data, programs, and documentation. The planning involves procedures for backing up the physical computer facilities, computer, and other equipment (such as communications equipment—a vital resource in the event of a catastrophe), supplies, and personnel. Furthermore, planning reaches beyond the IS function to provide backup for these same resources residing in operational business units of the organization. Finally, the plan may extend beyond the organization for key resources provided by third parties. You might also note that the current thinking is that we plan contingencies for important processesrather than individual resources. So, we develop a contingency plan for our Internet presence, rather than for our Web servers, networks, and other related resources that enable that presence.
|
|
Numerous disaster backup and recovery strategies may be included in an organization’s contingency plan. Some industries require instant recovery and must incur the cost of maintaining two or more sites. One such option is to run two processing sites, a primary and a mirror site that maintains copies of the primary site’s programs and data. During normal processing activities, master data is updated at both the primary and mirror sites. Located miles away from the primary site, the mirror site can take over in seconds if the primary site goes down. Mirror sites are very popular with airline and e-business organizations because they need to keep their systems and Internet commerce sites online at all times. Server clustering can also be used to disperse processing load among servers so that if one server fails, another can take over. 1 These clustered servers are essentially mirror sites for each other. |
|
|
Here is one example of the importance of these contingency processes to e-business. In June 1999 the Web site for eBay, Inc., the online auctioneer, was unavailable for 22 hours. This downtime caused eBay to forego $3 to $5 million in fees and some erosion of customer loyalty. This failure spurred eBay to accelerate its plans for a better backup system. 2 |
For most companies, maintaining duplicate equipment is simply cost-prohibitive. Therefore, a good control strategy is to make arrangements with hardware vendors, service centers, or others for the standby use of compatible computer equipment. These arrangements are generally of two types—hot sites or cold sites.
|
Review Question What is the difference between a hot site and a cold site? |
A hot site is a fully equipped data center, often housed in bunker-like facilities, that can accommodate many businesses—sometimes up to 100 companies—and that is made available to client companies for a monthly subscriber’s fee. Less costly, but obviously less responsive, is a cold site. It is a facility usually comprising air-conditioned space with a raised floor, telephone connections, and computer ports, into which a subscriber can move equipment. The disaster recovery contractor or the manufacturer provides the necessary equipment.
|
|
Ensuring continuous service in a centralized environment has become fairly straightforward. We know that we need to back up important databases, programs, and documentation, move those backups to recovery sites, and begin processing at that site. However, ISF environments are seldom that centralized; there are usually client-server applications and other distributed applications and connections. For example, a company may be doing business on the Internet and would need to include that application in their continuity plan. Technology Insight 8.3 describes several lessons about ensuring continuous service that were learned as a result of the events of September 11, 2001. |

|
In the spring of 2000, several organizations, including Yahoo!, eBay, CNN.com, and Amazon.com, experienced a serious threat to their ability to ensure continuous service to their customers. The culprit was a relatively new phenomenon, the distributed denial of service attack. Technology Insight 8.4 describes these attacks and the processes that might be put in place to detect and correct them to ensure that organizations achieve the level of service that they plan. The Yankee Group estimated that the overall cost of these attacks was $1.2 billion. For example, the Yahoo! Site was unavailable for three hours, which cost Yahoo! $500,000. Amazon’s site was down for an hour, resulting in a likely loss of $240,000. 3 |
Restrict Access to Computing Resources
Can you believe that 90 percent of the respondents to a survey conducted by the Computer Security Institute (CSI) with the participation of the San Francisco Federal Bureau of Investigation’s Computer Intrusion Squad reported security breaches in a recent 12-month period? 4
Technology Insight 8.3
Business and IT Continuity Lessons Learnedas a Result of September 11, 2001
- Hot sites and cold sites were overwhelmed by the demands for their use by businesses located in and around the WTC. Contracts with these sites must now specify who gets priority for their use.
- Backup and recovery locations must not be located in proximity to the primary site. Some organizations stored their backup data within the WTC complex.
- There must be several post-disaster communication options, including multiple telephone carriers, cell phones, and e-mail. Some telephone and cell phone services were not available in the WTC area for months after the disaster.
- Employees calling in was much more effective than trying to call out to determine the status and location of employees.
- Several organizations, especially those in financial services, realized that they needed their IT resources to be continuously available (i.e., preventive) rather than to be recovered after the disaster (i.e., corrective).
- Contingency plans must include alternative modes of transportation and should locate recovery sites near where employees live. For several days after 9/11, airlines did not fly, rental cars were hard to find, train and bus systems were severely taxed, and some roads, tunnels, and bridges were closed.
- Paperless offices are only an illusion and back-ups must be created for paper documents using digital imaging and other technologies. Organizations lost copies of paper documents and recordings of meetings and legal depositions.
To ensure that organizational information is not subjected to unauthorized use, disclosure, modification, damage, or loss, management should implement logical and physical access controls to assure that access to computing resources—systems, data, and programs—is restricted to authorized users for authorized uses by implementing two types of plans:
- Control plans that restrict physical access to computer facilities.
- Control plans that restrict logical access to stored programs, data, and documentation.
|
Review Question What are the control plans for restricting access to computer facilities? What three “layers” of control do these plans represent? Explain each layer. |
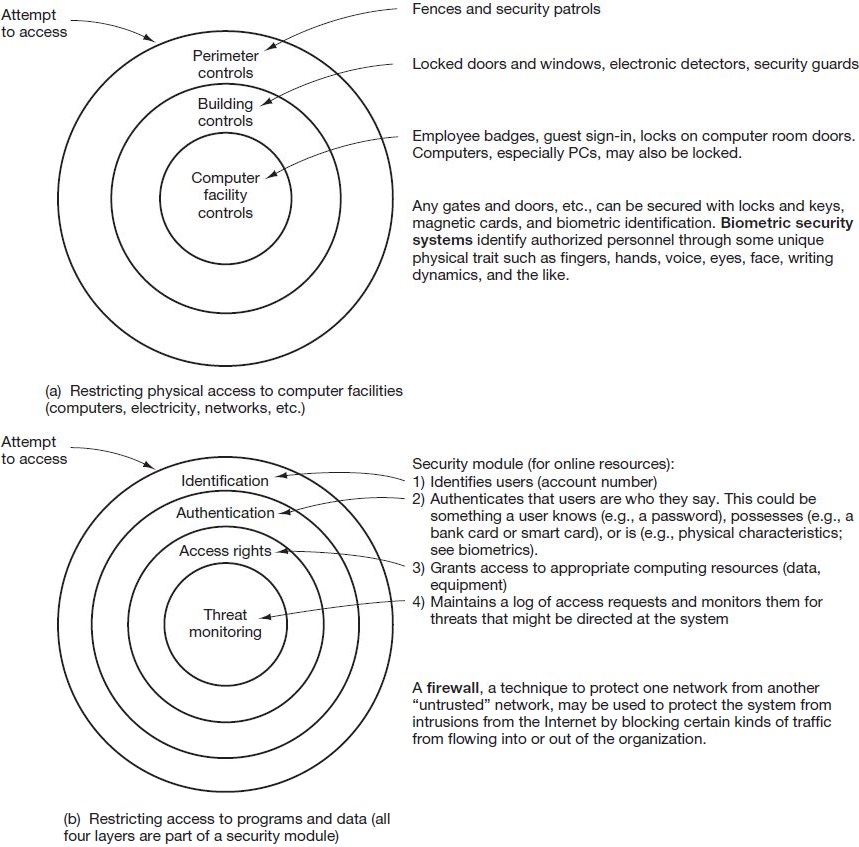
Figure 8.4 shows the levels (or layers) of protection included in these two categories.
Control plans for restricting physical access to computer facilities. Naturally, only authorized personnel should be allowed access to the computer facility. As shown in the top portion of Figure 8.4, control plans for restricting physical access to computer facilities encompass three layers of controls.
Technology Insight 8.4
Denial of Service Attacks
In a denial of service attack, a Web site is overwhelmed by an intentional onslaught of thousands of simultaneous messages, making it impossible for the attacked site to engage in its normal activities. A distributed denial of service attack uses many computers (called “zombies”) that unwittingly cooperate in a denial of service attack by sending messages to the target Web sites. Unfortunately, the distributed version is more effective because the number of computers responding multiplies the number of attack messages. And, because each computer has its own IP address, it is more difficult to detect that an attack is taking place than it would be if all the messages were coming from one address.
Currently there are no easy preventive controls. To detect a denial of service attack, Web sites may employ filters to detect the multiple messages and block traffic from the sites sending them, and switches to move their legitimate traffic to servers and Internet Service Providers (ISPs) that are not under attack (i.e., corrective action). However, attackers can hide their identity by creating false IP addresses for each message, making many filtering defenses slow to respond or virtually ineffective. An organization might also carry insurance to reimburse them for any losses suffered from an attack (i.e., corrective).
|
Review Question What are the control plans for restricting access to stored programs, data, and documentation? Which of these plans apply to an online environment, and which plans apply to an offline environment? How does a security module work? |
Control plans for restricting access to stored programs, data, and documentation.Control plans for restricting access to stored programs, data, and documentation entail a number of techniques aimed at controlling online and offline systems. In an online environment, access control software called the security module will ensure that only authorized users gain access to a system and report violation attempts. These steps are depicted in the lower portion of Figure 8.4.
|
Review Question What kinds of damage are included in the category of environmental hazards? What control plans are designed to prevent such hazards from occurring? What control plans are designed to limit losses resulting from such hazards or to recover from such hazards? |
The primary plans for restricting access in an offline environment involve the use of segregation of duties, restriction of access to computer facilities, program change controls, and library controls. The first three plans have been defined and discussed in previous sections. Library controls restrict access to data, programs, and documentation. Library controls are provided by a librarian function, a combination of people, procedures, and computer software. Librarian software can keep track of versions of event and master data and ensure that the correct versions of such data are used. The software can also permit appropriate access to development, testing, staging, and production versions of programs (see Figure 8.3).
Ensure Physical Security
To protect IT facilities against manmade and natural hazards, the organization must install and regularly review suitable environmental and physical controls. These plans reduce losses caused by a variety of physical, mechanical, and environmental events. Table 8.6 summarizes some of the more common controls directed at these environmental hazards.
The advanced state of today’s hardware technology results in a high degree of equipment reliability. Even if a malfunction does occur, it is usually detected and corrected automatically. In addition to relying on the controls contained within the computer hardware, organizations should perform regular preventive maintenance (periodic cleaning, testing, and adjusting of computer equipment) to ensure its continued efficient and correct operation.
- 6415 reads
